Beautiful Racket / tutorials
- 1 intro
- 2 specification and setup
- 3 the lexer
- 4 the tokenizer
- 5 the parser
- 6 the reader
- 7 the expander
- 8 testing the language
- 9 recap
- 10 source listing
basic/parser.rkt
#lang brag
b-program : b-line (NEWLINE b-line)*
b-line :
b-program : b-line (NEWLINE b-line)*
b-line :
1 2 3 | #lang brag b-program : b-line (NEWLINE b-line)* b-line : |

sample.rkt
#lang basic
30 rem print 'ignored'
35
50 print "never gets here"
40 end
60 print 'three' : print 1.0 + 3
70 goto 11. + 18.5 + .5 rem ignored
10 print "o" ; "n" ; "e"
20 print : goto 60.0 : end
30 rem print 'ignored'
35
50 print "never gets here"
40 end
60 print 'three' : print 1.0 + 3
70 goto 11. + 18.5 + .5 rem ignored
10 print "o" ; "n" ; "e"
20 print : goto 60.0 : end
1 2 3 4 5 6 7 8 9 | #lang basic 30 rem print 'ignored' 35 50 print "never gets here" 40 end 60 print 'three' : print 1.0 + 3 70 goto 11. + 18.5 + .5 rem ignored 10 print "o" ; "n" ; "e" 20 print : goto 60.0 : end |
#lang basic
1 | #lang basic |
#lang basic
1 2 3 4 5 | #lang basic
|
#lang basic
10 print "hello world"
20 goto 10
10 print "hello world"
20 goto 10
1 2 3 4 5 6 7 8 | #lang basic 10 print "hello world" 20 goto 10 |
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line :
b-program : [b-line] (NEWLINE [b-line])*
b-line :
1 2 3 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line :
|
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num
| b-line-num b-statement
| b-line-num b-statement (":" b-statement)+
b-line-num : INTEGER
b-statement :
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num
| b-line-num b-statement
| b-line-num b-statement (":" b-statement)+
b-line-num : INTEGER
b-statement :
1 2 3 4 5 6 7 | #lang brag b-program : [b-line] (NEWLINE [b-line])* b-line : b-line-num | b-line-num b-statement | b-line-num b-statement (":" b-statement)+ b-line-num : INTEGER b-statement : |
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement (":" b-statement)*]
b-line-num : INTEGER
b-statement :
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement (":" b-statement)*]
b-line-num : INTEGER
b-statement :
1 2 3 4 5 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement (":" b-statement)*]
b-line-num : INTEGER
b-statement :
|
10 print "foo" :
20 : print "bar" : :
30 :::
20 : print "bar" : :
30 :::
1 2 3 | 10 print "foo" : 20 : print "bar" : : 30 ::: |
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])*
b-line-num : INTEGER
b-statement :
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])*
b-line-num : INTEGER
b-statement :
1 2 3 4 5 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])*
b-line-num : INTEGER
b-statement :
|
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement :
b-rem : REM
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement :
b-rem : REM
1 2 3 4 5 6 | #lang brag b-program : [b-line] (NEWLINE [b-line])* b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem] b-line-num : INTEGER b-statement : b-rem : REM |
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end :
b-print :
b-goto :
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end :
b-print :
b-goto :
1 2 3 4 5 6 7 8 9 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end :
b-print :
b-goto :
|
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print :
b-goto :
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print :
b-goto :
1 2 3 4 5 6 7 8 9 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print :
b-goto :
|
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto :
b-expr :
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto :
b-expr :
1 2 3 4 5 6 7 8 9 10 11 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto :
b-expr :
|
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
1 2 3 4 5 6 7 8 9 10 11 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
|
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
b-sum :
b-number : INTEGER | DECIMAL
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
b-sum :
b-number : INTEGER | DECIMAL
1 2 3 4 5 6 7 8 9 10 11 12 13 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
b-sum :
b-number : INTEGER | DECIMAL
|
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
b-sum : b-number ("+" b-number)*
b-number : INTEGER | DECIMAL
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
b-sum : b-number ("+" b-number)*
b-number : INTEGER | DECIMAL
1 2 3 4 5 6 7 8 9 10 11 12 13 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr :
b-sum : b-number ("+" b-number)*
b-number : INTEGER | DECIMAL
|
basic/parser.rkt
#lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr : b-sum
b-sum : b-number ("+" b-number)*
b-number : INTEGER | DECIMAL
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr : b-sum
b-sum : b-number ("+" b-number)*
b-number : INTEGER | DECIMAL
1 2 3 4 5 6 7 8 9 10 11 12 13 | #lang brag
b-program : [b-line] (NEWLINE [b-line])*
b-line : b-line-num [b-statement] (":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : "end"
b-print : "print" [b-printable] (";" [b-printable])*
b-printable : STRING | b-expr
b-goto : "goto" b-expr
b-expr : b-sum
b-sum : b-number ("+" b-number)*
b-number : INTEGER | DECIMAL
|
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
20 goto 9 + 10 + 11
30 end
1 2 3 | 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
parser-test.rkt
#lang br
(require basic/parser basic/tokenizer brag/support)
(define str #<<HERE
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
HERE
)
(parse-to-datum (apply-tokenizer make-tokenizer str))
(require basic/parser basic/tokenizer brag/support)
(define str #<<HERE
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
HERE
)
(parse-to-datum (apply-tokenizer make-tokenizer str))
1 2 3 4 5 6 7 8 9 10 11 | #lang br (require basic/parser basic/tokenizer brag/support) (define str #<<HERE 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end HERE ) (parse-to-datum (apply-tokenizer make-tokenizer str)) |
'(b-program
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world"))))
"\n"
(b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11))))))
"\n"
(b-line (b-line-num 30) (b-statement (b-end "end"))))
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world"))))
"\n"
(b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11))))))
"\n"
(b-line (b-line-num 30) (b-statement (b-end "end"))))
1 2 3 4 5 6 | '(b-program (b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world")))) "\n" (b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11)))))) "\n" (b-line (b-line-num 30) (b-statement (b-end "end")))) |
sample.rkt
#lang basic
30 rem print 'ignored'
35
50 print "never gets here"
40 end
60 print 'three' : print 1.0 + 3
70 goto 11. + 18.5 + .5 rem ignored
10 print "o" ; "n" ; "e"
20 print : goto 60.0 : end
30 rem print 'ignored'
35
50 print "never gets here"
40 end
60 print 'three' : print 1.0 + 3
70 goto 11. + 18.5 + .5 rem ignored
10 print "o" ; "n" ; "e"
20 print : goto 60.0 : end
1 2 3 4 5 6 7 8 9 | #lang basic 30 rem print 'ignored' 35 50 print "never gets here" 40 end 60 print 'three' : print 1.0 + 3 70 goto 11. + 18.5 + .5 rem ignored 10 print "o" ; "n" ; "e" 20 print : goto 60.0 : end |
parser-test.rkt
#lang br
(require basic/parser basic/tokenizer brag/support)
(define str #<<HERE
30 rem print 'ignored'
35
50 print "never gets here"
40 end
60 print 'three' : print 1.0 + 3
70 goto 11. + 18.5 + .5 rem ignored
10 print "o" ; "n" ; "e"
20 print : goto 60.0 : end
HERE
)
(parse-to-datum (apply-tokenizer make-tokenizer str))
(require basic/parser basic/tokenizer brag/support)
(define str #<<HERE
30 rem print 'ignored'
35
50 print "never gets here"
40 end
60 print 'three' : print 1.0 + 3
70 goto 11. + 18.5 + .5 rem ignored
10 print "o" ; "n" ; "e"
20 print : goto 60.0 : end
HERE
)
(parse-to-datum (apply-tokenizer make-tokenizer str))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | #lang br (require basic/parser basic/tokenizer brag/support) (define str #<<HERE 30 rem print 'ignored' 35 50 print "never gets here" 40 end 60 print 'three' : print 1.0 + 3 70 goto 11. + 18.5 + .5 rem ignored 10 print "o" ; "n" ; "e" 20 print : goto 60.0 : end HERE ) (parse-to-datum (apply-tokenizer make-tokenizer str)) |
'(b-program
(b-line (b-line-num 30) (b-rem "rem print 'ignored'"))
"\n"
(b-line (b-line-num 35))
"\n"
(b-line (b-line-num 50) (b-statement (b-print "print" (b-printable "never gets here"))))
"\n"
(b-line (b-line-num 40) (b-statement (b-end "end")))
"\n"
(b-line
(b-line-num 60)
(b-statement (b-print "print" (b-printable "three")))
":"
(b-statement (b-print "print" (b-printable (b-expr (b-sum (b-number 1.0) "+" (b-number 3)))))))
"\n"
(b-line
(b-line-num 70)
(b-statement (b-goto "goto" (b-expr (b-sum (b-number 11.0) "+" (b-number 18.5) "+" (b-number 0.5)))))
(b-rem "rem ignored"))
"\n"
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "o") ";" (b-printable "n") ";" (b-printable "e"))))
"\n"
(b-line
(b-line-num 20)
(b-statement (b-print "print"))
":"
(b-statement (b-goto "goto" (b-expr (b-sum (b-number 60.0)))))
":"
(b-statement (b-end "end"))))
(b-line (b-line-num 30) (b-rem "rem print 'ignored'"))
"\n"
(b-line (b-line-num 35))
"\n"
(b-line (b-line-num 50) (b-statement (b-print "print" (b-printable "never gets here"))))
"\n"
(b-line (b-line-num 40) (b-statement (b-end "end")))
"\n"
(b-line
(b-line-num 60)
(b-statement (b-print "print" (b-printable "three")))
":"
(b-statement (b-print "print" (b-printable (b-expr (b-sum (b-number 1.0) "+" (b-number 3)))))))
"\n"
(b-line
(b-line-num 70)
(b-statement (b-goto "goto" (b-expr (b-sum (b-number 11.0) "+" (b-number 18.5) "+" (b-number 0.5)))))
(b-rem "rem ignored"))
"\n"
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "o") ";" (b-printable "n") ";" (b-printable "e"))))
"\n"
(b-line
(b-line-num 20)
(b-statement (b-print "print"))
":"
(b-statement (b-goto "goto" (b-expr (b-sum (b-number 60.0)))))
":"
(b-statement (b-end "end"))))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | '(b-program (b-line (b-line-num 30) (b-rem "rem print 'ignored'")) "\n" (b-line (b-line-num 35)) "\n" (b-line (b-line-num 50) (b-statement (b-print "print" (b-printable "never gets here")))) "\n" (b-line (b-line-num 40) (b-statement (b-end "end"))) "\n" (b-line (b-line-num 60) (b-statement (b-print "print" (b-printable "three"))) ":" (b-statement (b-print "print" (b-printable (b-expr (b-sum (b-number 1.0) "+" (b-number 3))))))) "\n" (b-line (b-line-num 70) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 11.0) "+" (b-number 18.5) "+" (b-number 0.5))))) (b-rem "rem ignored")) "\n" (b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "o") ";" (b-printable "n") ";" (b-printable "e")))) "\n" (b-line (b-line-num 20) (b-statement (b-print "print")) ":" (b-statement (b-goto "goto" (b-expr (b-sum (b-number 60.0))))) ":" (b-statement (b-end "end")))) |
test.rkt
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
1 2 3 4 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
'(b-program
"\n"
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world"))))
"\n"
(b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11))))))
"\n"
(b-line (b-line-num 30) (b-statement (b-end "end")))
"\n")
"\n"
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world"))))
"\n"
(b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11))))))
"\n"
(b-line (b-line-num 30) (b-statement (b-end "end")))
"\n")
1 2 3 4 5 6 7 8 | '(b-program "\n" (b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world")))) "\n" (b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11)))))) "\n" (b-line (b-line-num 30) (b-statement (b-end "end"))) "\n") |
basic/parse-only.rkt
#lang br/quicklang
(require "parser.rkt" "tokenizer.rkt")
(define (read-syntax path port)
(define parse-tree (parse path (make-tokenizer port path)))
(strip-bindings
#`(module basic-parser-mod basic/parse-only
#,parse-tree)))
(module+ reader (provide read-syntax))
(define-macro (parser-only-mb PARSE-TREE)
#'(#%module-begin
'PARSE-TREE))
(provide (rename-out [parser-only-mb #%module-begin]))
(require "parser.rkt" "tokenizer.rkt")
(define (read-syntax path port)
(define parse-tree (parse path (make-tokenizer port path)))
(strip-bindings
#`(module basic-parser-mod basic/parse-only
#,parse-tree)))
(module+ reader (provide read-syntax))
(define-macro (parser-only-mb PARSE-TREE)
#'(#%module-begin
'PARSE-TREE))
(provide (rename-out [parser-only-mb #%module-begin]))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #lang br/quicklang (require "parser.rkt" "tokenizer.rkt") (define (read-syntax path port) (define parse-tree (parse path (make-tokenizer port path))) (strip-bindings #`(module basic-parser-mod basic/parse-only #,parse-tree))) (module+ reader (provide read-syntax)) (define-macro (parser-only-mb PARSE-TREE) #'(#%module-begin 'PARSE-TREE)) (provide (rename-out [parser-only-mb #%module-begin])) |
test.rkt
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
1 2 3 4 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
'(b-program
"\n"
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world"))))
"\n"
(b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11))))))
"\n"
(b-line (b-line-num 30) (b-statement (b-end "end")))
"\n")
"\n"
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world"))))
"\n"
(b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11))))))
"\n"
(b-line (b-line-num 30) (b-statement (b-end "end")))
"\n")
1 2 3 4 5 6 7 8 | '(b-program "\n" (b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world")))) "\n" (b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11)))))) "\n" (b-line (b-line-num 30) (b-statement (b-end "end"))) "\n") |
test.rkt
#lang basic-demo
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
1 2 3 4 | #lang basic-demo 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
hello
world
world
1 2 | hello world |
basic/tokenize-only.rkt
#lang br/quicklang
(require brag/support "tokenizer.rkt")
(define (read-syntax path port)
(define tokens (apply-tokenizer make-tokenizer port))
(strip-bindings
#`(module basic-tokens-mod basic/tokenize-only
#,@tokens)))
(module+ reader (provide read-syntax))
(define-macro (tokenize-only-mb TOKEN ...)
#'(#%module-begin
(list TOKEN ...)))
(provide (rename-out [tokenize-only-mb #%module-begin]))
(require brag/support "tokenizer.rkt")
(define (read-syntax path port)
(define tokens (apply-tokenizer make-tokenizer port))
(strip-bindings
#`(module basic-tokens-mod basic/tokenize-only
#,@tokens)))
(module+ reader (provide read-syntax))
(define-macro (tokenize-only-mb TOKEN ...)
#'(#%module-begin
(list TOKEN ...)))
(provide (rename-out [tokenize-only-mb #%module-begin]))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | #lang br/quicklang (require brag/support "tokenizer.rkt") (define (read-syntax path port) (define tokens (apply-tokenizer make-tokenizer port)) (strip-bindings #`(module basic-tokens-mod basic/tokenize-only #,@tokens))) (module+ reader (provide read-syntax)) (define-macro (tokenize-only-mb TOKEN ...) #'(#%module-begin (list TOKEN ...))) (provide (rename-out [tokenize-only-mb #%module-begin])) |
test.rkt
#lang basic/tokenize-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
1 2 3 4 | #lang basic/tokenize-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
(list
(srcloc-token (token-struct 'NEWLINE "\n" #f #f #f #f #f) (srcloc 'unsaved-editor 1 28 29 1))
(srcloc-token (token-struct 'INTEGER 10 #f #f #f #f #f) (srcloc 'unsaved-editor 2 0 30 2))
(srcloc-token (token-struct '| | #f #f #f #f #f #t) (srcloc 'unsaved-editor 2 2 32 1))
(srcloc-token (token-struct 'print "print" #f #f #f #f #f) (srcloc 'unsaved-editor 3 3 36 5))
···
(srcloc-token (token-struct 'NEWLINE "\n" #f #f #f #f #f) (srcloc 'unsaved-editor 1 28 29 1))
(srcloc-token (token-struct 'INTEGER 10 #f #f #f #f #f) (srcloc 'unsaved-editor 2 0 30 2))
(srcloc-token (token-struct '| | #f #f #f #f #f #t) (srcloc 'unsaved-editor 2 2 32 1))
(srcloc-token (token-struct 'print "print" #f #f #f #f #f) (srcloc 'unsaved-editor 3 3 36 5))
···
1 2 3 4 5 6 | (list (srcloc-token (token-struct 'NEWLINE "\n" #f #f #f #f #f) (srcloc 'unsaved-editor 1 28 29 1)) (srcloc-token (token-struct 'INTEGER 10 #f #f #f #f #f) (srcloc 'unsaved-editor 2 0 30 2)) (srcloc-token (token-struct '| | #f #f #f #f #f #t) (srcloc 'unsaved-editor 2 2 32 1)) (srcloc-token (token-struct 'print "print" #f #f #f #f #f) (srcloc 'unsaved-editor 3 3 36 5)) ··· |
test.rkt
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
1 2 3 4 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
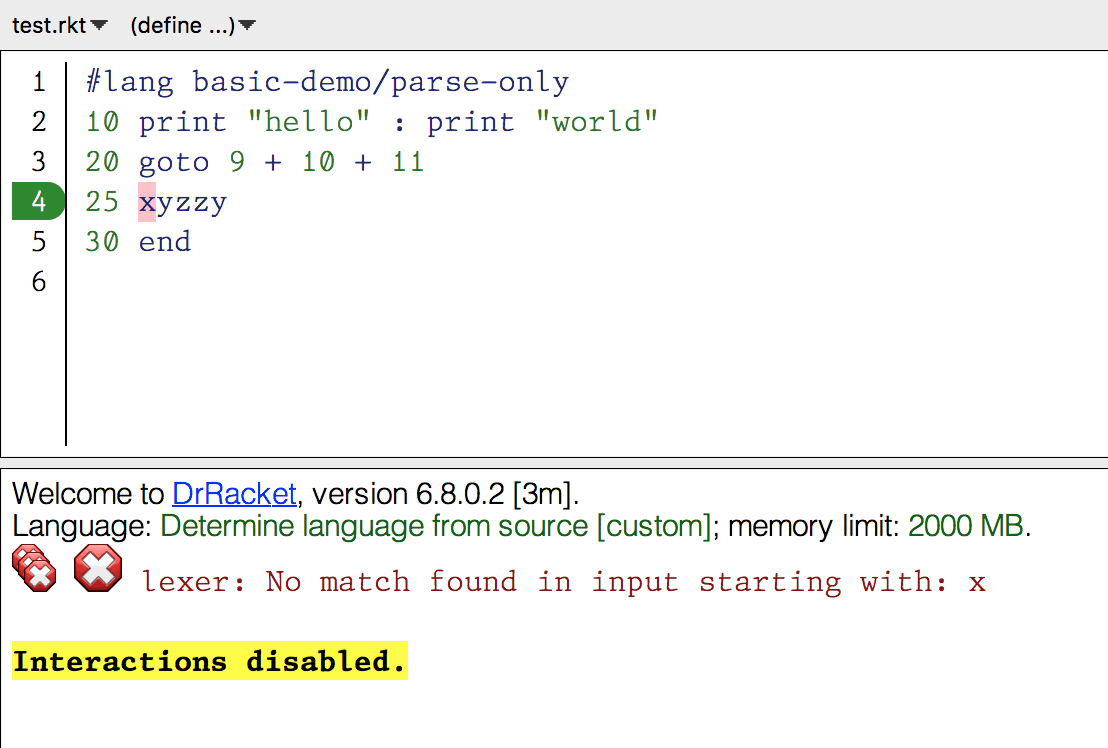
test.rkt
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
25 xyzzy
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
25 xyzzy
30 end
1 2 3 4 5 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 25 xyzzy 30 end |
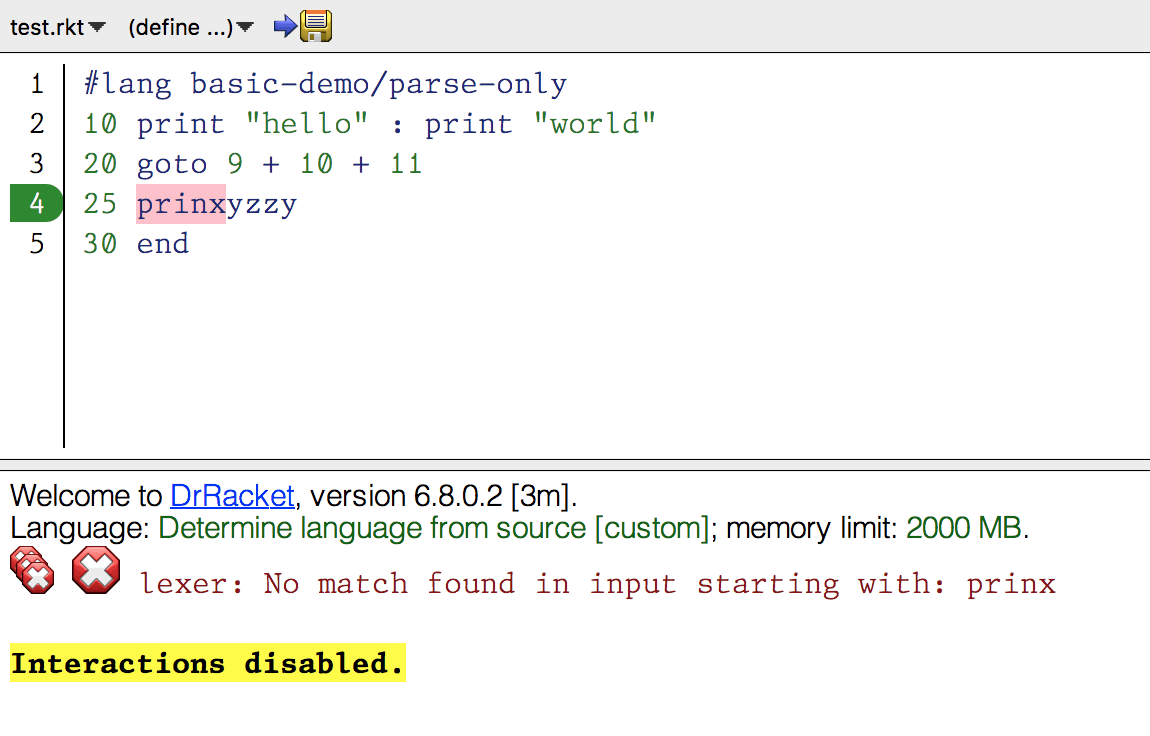
test.rkt
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
25 prinxyzzy
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
25 prinxyzzy
30 end
1 2 3 4 5 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 25 prinxyzzy 30 end |
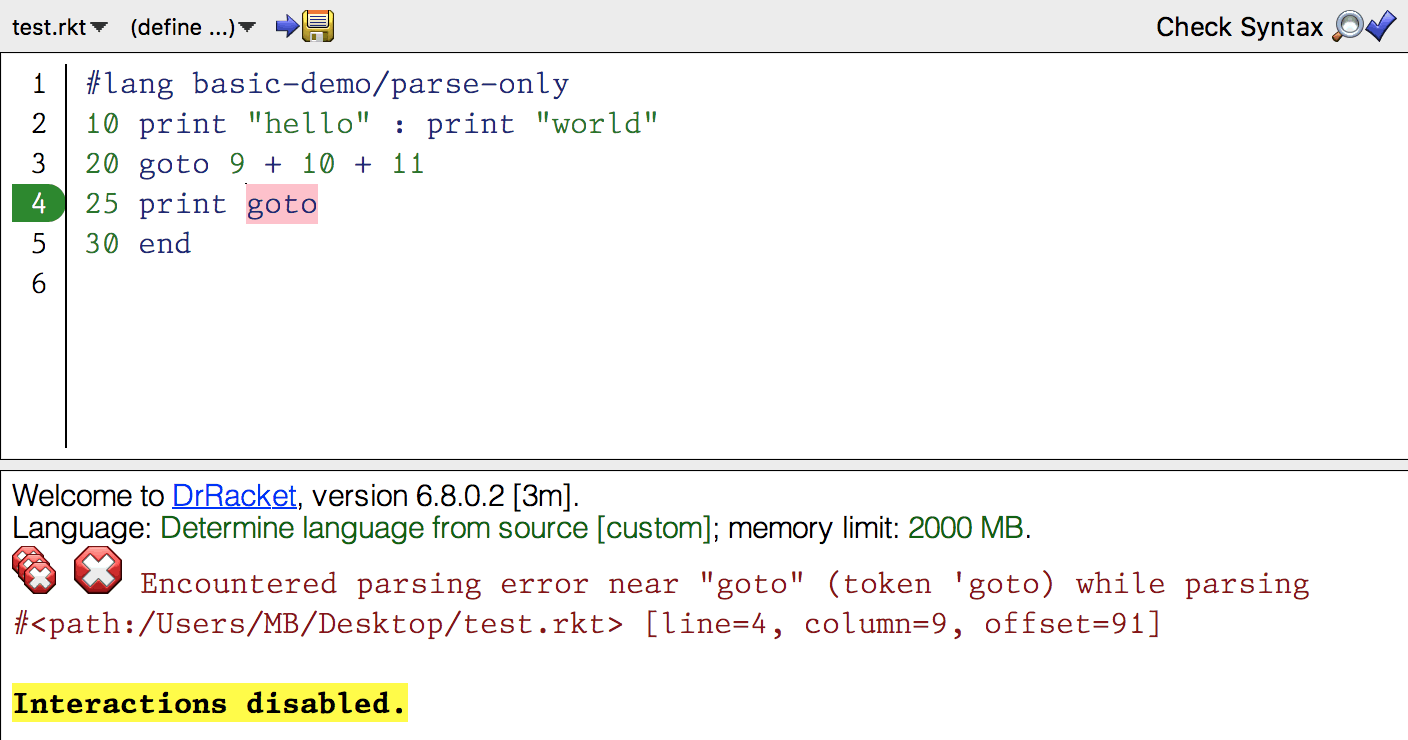
test.rkt
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
25 print goto
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
25 print goto
30 end
1 2 3 4 5 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 25 print goto 30 end |
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
1 2 3 4 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
'(b-program
"\n"
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world"))))
"\n"
(b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11))))))
"\n"
(b-line (b-line-num 30) (b-statement (b-end "end"))))
"\n"
(b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world"))))
"\n"
(b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11))))))
"\n"
(b-line (b-line-num 30) (b-statement (b-end "end"))))
1 2 3 4 5 6 7 | '(b-program "\n" (b-line (b-line-num 10) (b-statement (b-print "print" (b-printable "hello"))) ":" (b-statement (b-print "print" (b-printable "world")))) "\n" (b-line (b-line-num 20) (b-statement (b-goto "goto" (b-expr (b-sum (b-number 9) "+" (b-number 10) "+" (b-number 11)))))) "\n" (b-line (b-line-num 30) (b-statement (b-end "end")))) |
'(b-program
(b-line 10 (b-print "hello") (b-print "world"))
(b-line 20 (b-goto (b-expr (b-sum 9 10 11))))
(b-line 30 (b-end)))
(b-line 10 (b-print "hello") (b-print "world"))
(b-line 20 (b-goto (b-expr (b-sum 9 10 11))))
(b-line 30 (b-end)))
1 2 3 4 | '(b-program (b-line 10 (b-print "hello") (b-print "world")) (b-line 20 (b-goto (b-expr (b-sum 9 10 11)))) (b-line 30 (b-end))) |
basic/parser.rkt
#lang brag
b-program : [b-line] (/NEWLINE [b-line])*
b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : /"end"
b-print : /"print" [b-printable] (/";" [b-printable])*
b-printable : STRING | b-expr
b-goto : /"goto" b-expr
b-expr : b-sum
b-sum : b-number (/"+" b-number)*
b-number : INTEGER | DECIMAL
b-program : [b-line] (/NEWLINE [b-line])*
b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem]
b-line-num : INTEGER
b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : /"end"
b-print : /"print" [b-printable] (/";" [b-printable])*
b-printable : STRING | b-expr
b-goto : /"goto" b-expr
b-expr : b-sum
b-sum : b-number (/"+" b-number)*
b-number : INTEGER | DECIMAL
1 2 3 4 5 6 7 8 9 10 11 12 13 | #lang brag b-program : [b-line] (/NEWLINE [b-line])* b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem] b-line-num : INTEGER b-statement : b-end | b-print | b-goto b-rem : REM b-end : /"end" b-print : /"print" [b-printable] (/";" [b-printable])* b-printable : STRING | b-expr b-goto : /"goto" b-expr b-expr : b-sum b-sum : b-number (/"+" b-number)* b-number : INTEGER | DECIMAL |
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
1 2 3 4 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
'(b-program
(b-line (b-line-num 10)
(b-statement (b-print (b-printable "hello")))
(b-statement (b-print (b-printable "world"))))
(b-line (b-line-num 20)
(b-statement (b-goto (b-expr (b-sum (b-number 9) (b-number 10) (b-number 11))))))
(b-line (b-line-num 30) (b-statement (b-end))))
(b-line (b-line-num 10)
(b-statement (b-print (b-printable "hello")))
(b-statement (b-print (b-printable "world"))))
(b-line (b-line-num 20)
(b-statement (b-goto (b-expr (b-sum (b-number 9) (b-number 10) (b-number 11))))))
(b-line (b-line-num 30) (b-statement (b-end))))
1 2 3 4 5 6 7 | '(b-program
(b-line (b-line-num 10)
(b-statement (b-print (b-printable "hello")))
(b-statement (b-print (b-printable "world"))))
(b-line (b-line-num 20)
(b-statement (b-goto (b-expr (b-sum (b-number 9) (b-number 10) (b-number 11))))))
(b-line (b-line-num 30) (b-statement (b-end))))
|
basic/parser.rkt
#lang brag
b-program : [b-line] (/NEWLINE [b-line])*
b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem]
@b-line-num : INTEGER
@b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : /"end"
b-print : /"print" [b-printable] (/";" [b-printable])*
@b-printable : STRING | b-expr
b-goto : /"goto" b-expr
b-expr : b-sum
b-sum : b-number (/"+" b-number)*
@b-number : INTEGER | DECIMAL
b-program : [b-line] (/NEWLINE [b-line])*
b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem]
@b-line-num : INTEGER
@b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : /"end"
b-print : /"print" [b-printable] (/";" [b-printable])*
@b-printable : STRING | b-expr
b-goto : /"goto" b-expr
b-expr : b-sum
b-sum : b-number (/"+" b-number)*
@b-number : INTEGER | DECIMAL
1 2 3 4 5 6 7 8 9 10 11 12 13 | #lang brag b-program : [b-line] (/NEWLINE [b-line])* b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem] @b-line-num : INTEGER @b-statement : b-end | b-print | b-goto b-rem : REM b-end : /"end" b-print : /"print" [b-printable] (/";" [b-printable])* @b-printable : STRING | b-expr b-goto : /"goto" b-expr b-expr : b-sum b-sum : b-number (/"+" b-number)* @b-number : INTEGER | DECIMAL |
#lang basic/parse-only
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
10 print "hello" : print "world"
20 goto 9 + 10 + 11
30 end
1 2 3 4 | #lang basic/parse-only 10 print "hello" : print "world" 20 goto 9 + 10 + 11 30 end |
'(b-program
(b-line 10 (b-print "hello") (b-print "world"))
(b-line 20 (b-goto (b-expr (b-sum 9 10 11))))
(b-line 30 (b-end)))
(b-line 10 (b-print "hello") (b-print "world"))
(b-line 20 (b-goto (b-expr (b-sum 9 10 11))))
(b-line 30 (b-end)))
1 2 3 4 | '(b-program (b-line 10 (b-print "hello") (b-print "world")) (b-line 20 (b-goto (b-expr (b-sum 9 10 11)))) (b-line 30 (b-end))) |
#lang basic/parse-only
30 rem print 'ignored'
35
50 print "never gets here"
40 end
60 print 'three' : print 1.0 + 3
70 goto 11. + 18.5 + .5 rem ignored
10 print "o" ; "n" ; "e"
20 print : goto 60.0 : end
30 rem print 'ignored'
35
50 print "never gets here"
40 end
60 print 'three' : print 1.0 + 3
70 goto 11. + 18.5 + .5 rem ignored
10 print "o" ; "n" ; "e"
20 print : goto 60.0 : end
1 2 3 4 5 6 7 8 9 | #lang basic/parse-only 30 rem print 'ignored' 35 50 print "never gets here" 40 end 60 print 'three' : print 1.0 + 3 70 goto 11. + 18.5 + .5 rem ignored 10 print "o" ; "n" ; "e" 20 print : goto 60.0 : end |
'(b-program
(b-line 30 (b-rem "rem print 'ignored'"))
(b-line 35)
(b-line 50 (b-print "never gets here"))
(b-line 40 (b-end))
(b-line 60 (b-print "three") (b-print (b-expr (b-sum 1.0 3))))
(b-line 70 (b-goto (b-expr (b-sum 11.0 18.5 0.5))) (b-rem "rem ignored"))
(b-line 10 (b-print "o" "n" "e"))
(b-line 20 (b-print) (b-goto (b-expr (b-sum 60.0))) (b-end)))
(b-line 30 (b-rem "rem print 'ignored'"))
(b-line 35)
(b-line 50 (b-print "never gets here"))
(b-line 40 (b-end))
(b-line 60 (b-print "three") (b-print (b-expr (b-sum 1.0 3))))
(b-line 70 (b-goto (b-expr (b-sum 11.0 18.5 0.5))) (b-rem "rem ignored"))
(b-line 10 (b-print "o" "n" "e"))
(b-line 20 (b-print) (b-goto (b-expr (b-sum 60.0))) (b-end)))
1 2 3 4 5 6 7 8 9 | '(b-program (b-line 30 (b-rem "rem print 'ignored'")) (b-line 35) (b-line 50 (b-print "never gets here")) (b-line 40 (b-end)) (b-line 60 (b-print "three") (b-print (b-expr (b-sum 1.0 3)))) (b-line 70 (b-goto (b-expr (b-sum 11.0 18.5 0.5))) (b-rem "rem ignored")) (b-line 10 (b-print "o" "n" "e")) (b-line 20 (b-print) (b-goto (b-expr (b-sum 60.0))) (b-end))) |
basic/parser.rkt
#lang brag
b-program : [b-line] (/NEWLINE [b-line])*
b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem]
@b-line-num : INTEGER
@b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : /"end"
b-print : /"print" [b-printable] (/";" [b-printable])*
@b-printable : STRING | b-expr
b-goto : /"goto" b-expr
b-expr : b-sum
b-sum : b-number (/"+" b-number)*
@b-number : INTEGER | DECIMAL
b-program : [b-line] (/NEWLINE [b-line])*
b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem]
@b-line-num : INTEGER
@b-statement : b-end | b-print | b-goto
b-rem : REM
b-end : /"end"
b-print : /"print" [b-printable] (/";" [b-printable])*
@b-printable : STRING | b-expr
b-goto : /"goto" b-expr
b-expr : b-sum
b-sum : b-number (/"+" b-number)*
@b-number : INTEGER | DECIMAL
1 2 3 4 5 6 7 8 9 10 11 12 13 | #lang brag b-program : [b-line] (/NEWLINE [b-line])* b-line : b-line-num [b-statement] (/":" [b-statement])* [b-rem] @b-line-num : INTEGER @b-statement : b-end | b-print | b-goto b-rem : REM b-end : /"end" b-print : /"print" [b-printable] (/";" [b-printable])* @b-printable : STRING | b-expr b-goto : /"goto" b-expr b-expr : b-sum b-sum : b-number (/"+" b-number)* @b-number : INTEGER | DECIMAL |