Beautiful Racket / tutorials
- 1 intro
- 2 setup
- 3 contracts
- 4 unit tests
- 5 source locations
- 6 drracket integration
- 7 syntax coloring
- 8 indenting
- 9 toolbar buttons
- 10 recap
- 11 source listing
--------------------
FAILURE
name: check-true
location: unsaved-editor:3:0
params: (#f)
expression: (check-true #f)
--------------------
FAILURE
name: check-true
location: unsaved-editor:3:0
params: (#f)
expression: (check-true #f)
--------------------
1 2 3 4 5 6 7 | -------------------- FAILURE name: check-true location: unsaved-editor:3:0 params: (#f) expression: (check-true #f) -------------------- |

let x be 42 / 0
1 | let x be 42 / 0 |
(define stx #'foobar)
(syntax-position stx) ; 24
(syntax-line stx) ; 2
(syntax-column stx); 14
(syntax-span stx) ; 6
(syntax-position stx) ; 24
(syntax-line stx) ; 2
(syntax-column stx); 14
(syntax-span stx) ; 6
1 2 3 4 5 | (define stx #'foobar) (syntax-position stx) ; 24 (syntax-line stx) ; 2 (syntax-column stx); 14 (syntax-span stx) ; 6 |
(require brag/support jsonic/tokenizer)
(apply-tokenizer-maker make-tokenizer "x")
(apply-tokenizer-maker make-tokenizer "x")
1 2 | (require brag/support jsonic/tokenizer) (apply-tokenizer-maker make-tokenizer "x") |
(list (token-struct 'CHAR-TOK "x" #f #f #f #f #f))
1 | (list (token-struct 'CHAR-TOK "x" #f #f #f #f #f)) |
jsonic/tokenizer.rkt
···
(define (make-tokenizer port)
(port-count-lines! port) ; <- turn on line & column counting
(define (next-token)
(define jsonic-lexer
(lexer
[(from/to "//" "\n") (next-token)]
[(from/to "@$" "$@")
(token 'SEXP-TOK (trim-ends "@$" lexeme "$@"))]
[any-char (token 'CHAR-TOK lexeme)]))
(jsonic-lexer port))
next-token)
(provide
(contract-out
[make-tokenizer (input-port? . -> . (-> jsonic-token?))]))
···
(define (make-tokenizer port)
(port-count-lines! port) ; <- turn on line & column counting
(define (next-token)
(define jsonic-lexer
(lexer
[(from/to "//" "\n") (next-token)]
[(from/to "@$" "$@")
(token 'SEXP-TOK (trim-ends "@$" lexeme "$@"))]
[any-char (token 'CHAR-TOK lexeme)]))
(jsonic-lexer port))
next-token)
(provide
(contract-out
[make-tokenizer (input-port? . -> . (-> jsonic-token?))]))
···
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | ··· (define (make-tokenizer port) (port-count-lines! port) ; <- turn on line & column counting (define (next-token) (define jsonic-lexer (lexer [(from/to "//" "\n") (next-token)] [(from/to "@$" "$@") (token 'SEXP-TOK (trim-ends "@$" lexeme "$@"))] [any-char (token 'CHAR-TOK lexeme)])) (jsonic-lexer port)) next-token) (provide (contract-out [make-tokenizer (input-port? . -> . (-> jsonic-token?))])) ··· |
jsonic/tokenizer.rkt
···
(define (make-tokenizer port)
(port-count-lines! port)
(define (next-token)
(define jsonic-lexer
(lexer
[(from/to "//" "\n") (next-token)]
[(from/to "@$" "$@")
(token 'SEXP-TOK (trim-ends "@$" lexeme "$@"))]
[any-char (token 'CHAR-TOK lexeme
#:position (pos lexeme-start)
#:line (line lexeme-start)
#:column (col lexeme-start)
#:span (- (pos lexeme-end)
(pos lexeme-start)))]))
(jsonic-lexer port))
next-token)
(provide
(contract-out
[make-tokenizer (input-port? . -> . (-> jsonic-token?))]))
···
(define (make-tokenizer port)
(port-count-lines! port)
(define (next-token)
(define jsonic-lexer
(lexer
[(from/to "//" "\n") (next-token)]
[(from/to "@$" "$@")
(token 'SEXP-TOK (trim-ends "@$" lexeme "$@"))]
[any-char (token 'CHAR-TOK lexeme
#:position (pos lexeme-start)
#:line (line lexeme-start)
#:column (col lexeme-start)
#:span (- (pos lexeme-end)
(pos lexeme-start)))]))
(jsonic-lexer port))
next-token)
(provide
(contract-out
[make-tokenizer (input-port? . -> . (-> jsonic-token?))]))
···
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | ··· (define (make-tokenizer port) (port-count-lines! port) (define (next-token) (define jsonic-lexer (lexer [(from/to "//" "\n") (next-token)] [(from/to "@$" "$@") (token 'SEXP-TOK (trim-ends "@$" lexeme "$@"))] [any-char (token 'CHAR-TOK lexeme #:position (pos lexeme-start) #:line (line lexeme-start) #:column (col lexeme-start) #:span (- (pos lexeme-end) (pos lexeme-start)))])) (jsonic-lexer port)) next-token) (provide (contract-out [make-tokenizer (input-port? . -> . (-> jsonic-token?))])) ··· |
jsonic/tokenizer.rkt
···
(define (make-tokenizer port)
(port-count-lines! port)
(define (next-token)
(define jsonic-lexer
(lexer
[(from/to "//" "\n") (next-token)]
[(from/to "@$" "$@")
(token 'SEXP-TOK (trim-ends "@$" lexeme "$@")
#:position (+ (pos lexeme-start) 2)
#:line (line lexeme-start)
#:column (+ (col lexeme-start) 2)
#:span (- (pos lexeme-end)
(pos lexeme-start) 4))]
[any-char (token 'CHAR-TOK lexeme
#:position (pos lexeme-start)
#:line (line lexeme-start)
#:column (col lexeme-start)
#:span (- (pos lexeme-end)
(pos lexeme-start)))]))
(jsonic-lexer port))
next-token)
(provide
(contract-out
[make-tokenizer (input-port? . -> . (-> jsonic-token?))]))
···
(define (make-tokenizer port)
(port-count-lines! port)
(define (next-token)
(define jsonic-lexer
(lexer
[(from/to "//" "\n") (next-token)]
[(from/to "@$" "$@")
(token 'SEXP-TOK (trim-ends "@$" lexeme "$@")
#:position (+ (pos lexeme-start) 2)
#:line (line lexeme-start)
#:column (+ (col lexeme-start) 2)
#:span (- (pos lexeme-end)
(pos lexeme-start) 4))]
[any-char (token 'CHAR-TOK lexeme
#:position (pos lexeme-start)
#:line (line lexeme-start)
#:column (col lexeme-start)
#:span (- (pos lexeme-end)
(pos lexeme-start)))]))
(jsonic-lexer port))
next-token)
(provide
(contract-out
[make-tokenizer (input-port? . -> . (-> jsonic-token?))]))
···
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | ··· (define (make-tokenizer port) (port-count-lines! port) (define (next-token) (define jsonic-lexer (lexer [(from/to "//" "\n") (next-token)] [(from/to "@$" "$@") (token 'SEXP-TOK (trim-ends "@$" lexeme "$@") #:position (+ (pos lexeme-start) 2) #:line (line lexeme-start) #:column (+ (col lexeme-start) 2) #:span (- (pos lexeme-end) (pos lexeme-start) 4))] [any-char (token 'CHAR-TOK lexeme #:position (pos lexeme-start) #:line (line lexeme-start) #:column (col lexeme-start) #:span (- (pos lexeme-end) (pos lexeme-start)))])) (jsonic-lexer port)) next-token) (provide (contract-out [make-tokenizer (input-port? . -> . (-> jsonic-token?))])) ··· |
(apply-tokenizer-maker make-tokenizer "@$ (+ 6 7) $@")
1 | (apply-tokenizer-maker make-tokenizer "@$ (+ 6 7) $@") |
jsonic/tokenizer.rkt
#lang br/quicklang
(require brag/support racket/contract)
(module+ test
(require rackunit))
(define (jsonic-token? x)
(or (eof-object? x) (token-struct? x)))
(module+ test
(check-true (jsonic-token? eof))
(check-true (jsonic-token? (token 'A-TOKEN-STRUCT "hi")))
(check-false (jsonic-token? 42)))
(define (make-tokenizer port)
(port-count-lines! port)
(define (next-token)
(define jsonic-lexer
(lexer
[(from/to "//" "\n") (next-token)]
[(from/to "@$" "$@")
(token 'SEXP-TOK (trim-ends "@$" lexeme "$@")
#:position (+ (pos lexeme-start) 2)
#:line (line lexeme-start)
#:column (+ (col lexeme-start) 2)
#:span (- (pos lexeme-end)
(pos lexeme-start) 4))]
[any-char (token 'CHAR-TOK lexeme
#:position (pos lexeme-start)
#:line (line lexeme-start)
#:column (col lexeme-start)
#:span (- (pos lexeme-end)
(pos lexeme-start)))]))
(jsonic-lexer port))
next-token)
(provide
(contract-out
[make-tokenizer (input-port? . -> . (-> jsonic-token?))]))
(module+ test
(check-equal?
(apply-tokenizer-maker make-tokenizer "// comment\n")
empty)
(check-equal?
(apply-tokenizer-maker make-tokenizer "@$ (+ 6 7) $@")
(list (token 'SEXP-TOK " (+ 6 7) "
#:position 3
#:line 1
#:column 2
#:span 9)))
(check-equal?
(apply-tokenizer-maker make-tokenizer "hi")
(list (token 'CHAR-TOK "h"
#:position 1
#:line 1
#:column 0
#:span 1)
(token 'CHAR-TOK "i"
#:position 2
#:line 1
#:column 1
#:span 1))))
(require brag/support racket/contract)
(module+ test
(require rackunit))
(define (jsonic-token? x)
(or (eof-object? x) (token-struct? x)))
(module+ test
(check-true (jsonic-token? eof))
(check-true (jsonic-token? (token 'A-TOKEN-STRUCT "hi")))
(check-false (jsonic-token? 42)))
(define (make-tokenizer port)
(port-count-lines! port)
(define (next-token)
(define jsonic-lexer
(lexer
[(from/to "//" "\n") (next-token)]
[(from/to "@$" "$@")
(token 'SEXP-TOK (trim-ends "@$" lexeme "$@")
#:position (+ (pos lexeme-start) 2)
#:line (line lexeme-start)
#:column (+ (col lexeme-start) 2)
#:span (- (pos lexeme-end)
(pos lexeme-start) 4))]
[any-char (token 'CHAR-TOK lexeme
#:position (pos lexeme-start)
#:line (line lexeme-start)
#:column (col lexeme-start)
#:span (- (pos lexeme-end)
(pos lexeme-start)))]))
(jsonic-lexer port))
next-token)
(provide
(contract-out
[make-tokenizer (input-port? . -> . (-> jsonic-token?))]))
(module+ test
(check-equal?
(apply-tokenizer-maker make-tokenizer "// comment\n")
empty)
(check-equal?
(apply-tokenizer-maker make-tokenizer "@$ (+ 6 7) $@")
(list (token 'SEXP-TOK " (+ 6 7) "
#:position 3
#:line 1
#:column 2
#:span 9)))
(check-equal?
(apply-tokenizer-maker make-tokenizer "hi")
(list (token 'CHAR-TOK "h"
#:position 1
#:line 1
#:column 0
#:span 1)
(token 'CHAR-TOK "i"
#:position 2
#:line 1
#:column 1
#:span 1))))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | #lang br/quicklang (require brag/support racket/contract) (module+ test (require rackunit)) (define (jsonic-token? x) (or (eof-object? x) (token-struct? x))) (module+ test (check-true (jsonic-token? eof)) (check-true (jsonic-token? (token 'A-TOKEN-STRUCT "hi"))) (check-false (jsonic-token? 42))) (define (make-tokenizer port) (port-count-lines! port) (define (next-token) (define jsonic-lexer (lexer [(from/to "//" "\n") (next-token)] [(from/to "@$" "$@") (token 'SEXP-TOK (trim-ends "@$" lexeme "$@") #:position (+ (pos lexeme-start) 2) #:line (line lexeme-start) #:column (+ (col lexeme-start) 2) #:span (- (pos lexeme-end) (pos lexeme-start) 4))] [any-char (token 'CHAR-TOK lexeme #:position (pos lexeme-start) #:line (line lexeme-start) #:column (col lexeme-start) #:span (- (pos lexeme-end) (pos lexeme-start)))])) (jsonic-lexer port)) next-token) (provide (contract-out [make-tokenizer (input-port? . -> . (-> jsonic-token?))])) (module+ test (check-equal? (apply-tokenizer-maker make-tokenizer "// comment\n") empty) (check-equal? (apply-tokenizer-maker make-tokenizer "@$ (+ 6 7) $@") (list (token 'SEXP-TOK " (+ 6 7) " #:position 3 #:line 1 #:column 2 #:span 9))) (check-equal? (apply-tokenizer-maker make-tokenizer "hi") (list (token 'CHAR-TOK "h" #:position 1 #:line 1 #:column 0 #:span 1) (token 'CHAR-TOK "i" #:position 2 #:line 1 #:column 1 #:span 1)))) |
//x
y
z
y
z
1 2 3 | //x y z |
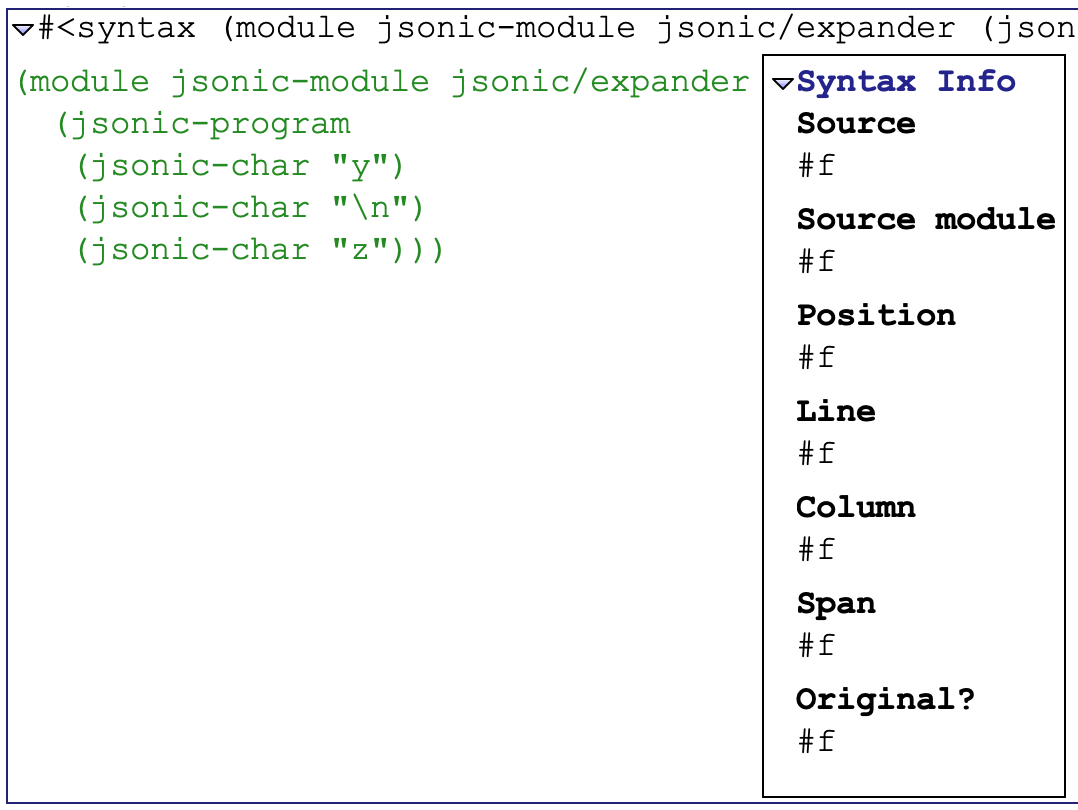
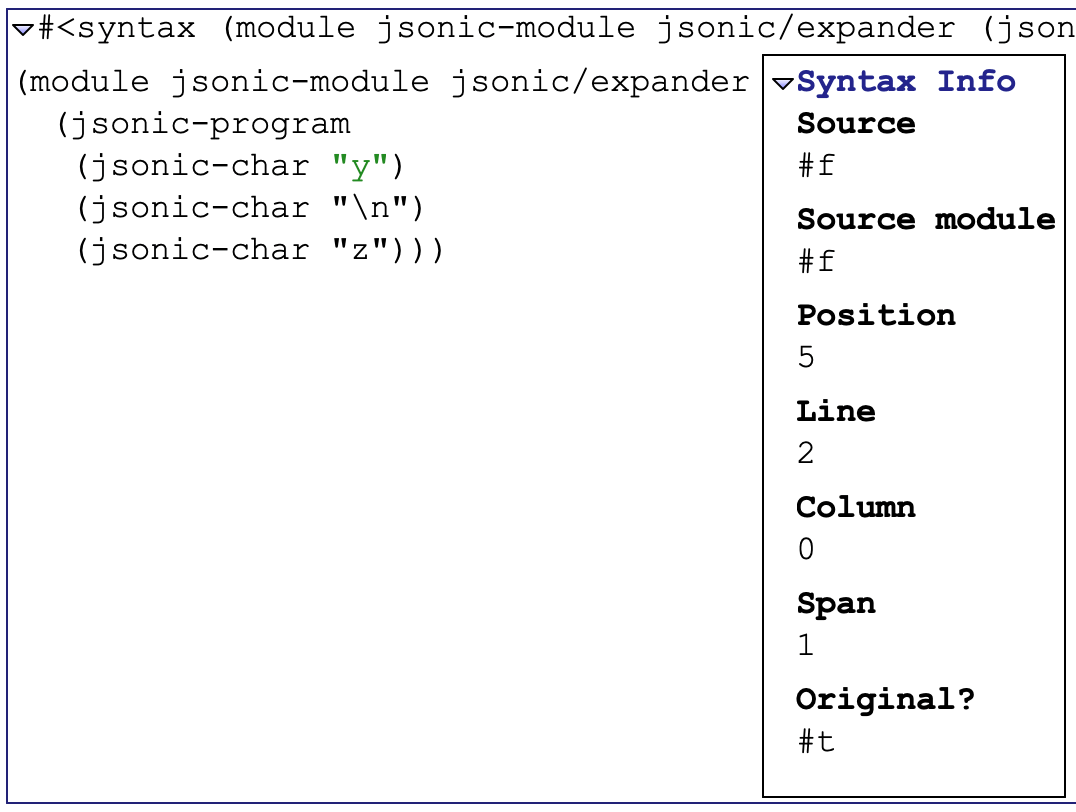
#<syntax (module jsonic-module jsonic/...>
1 | > #<syntax (module jsonic-module jsonic/...> |